
티스토리 뷰
[Day 12] 최적화
1. 강의 복습 내용
1) Deep Learning - Optimization
Deep Learning - Optimization
1. Important Concepts in Optimization
1) Generalization
- 일반화 성능을 높이는 것이 목적
- Training error 와 Test error의 차이 - Generalization Gap
(즉, Generalization이 좋다 -> 모델의 성능(테스트결과)이 학습 데이터와 비슷하게 나온다)

2) Under-fitting vs Over-fitting
Over-fitting
- 학습 데이터에 대해서 잘 동작하지만, 테스트 데이터에 대해서 잘 동작하지 않는 현상 (과적합)
Under-fitting
- 네트워크가 너무 간단하거나, Train이 부족해서 학습데이터, 테스트데이터 둘다 잘 못맞춤
따라서,
- Train Data와 Test Data를 나눠서 줌
- Train Data로 학습시킨 모델이, 학습에 사용되지 않은 Validation data기준으로 얼마나 잘 작동하는 지 보는 것
-> 얼마나 데이터를 Train Data와 Test Data로 나누는 것이 좋은가? -> Cross validation

3) Cross validation ( K Fold )
- K개의 Fold로 데이터를 나누어서 학습
- K개로 Partitioning 후 K-1개로 학습을 하고 나머지 1개로 Validation을 해보는 것
- Cross-validation -> 최적의 Hyperparameter set을 찾는다 -> 보정 후 학습시킬 때는 모든 Data를 동원
- Test Data는 절대 사용하면 안된다.

4) Bias-variance tradeoff
Variance : 내가 어떤 입력을 넣었을때 출력이 얼마나 일관적으로 나오는 지를 말함 (Low <-> High)
Bias : 평균적으로 봤을 때, True Target과 얼마나 벗어나 있는지 (Low <-> High)
-> High가 부정적

내 학습 학습데이터에 노이즈가 껴있는 것을 가정했을 때, 이 노이즈가 껴있는 Target Data를 Minimize 하는 것은 3가지 Part로 나뉠 수 있다.

근본적으로, 학습데이터에 노이즈가 껴있을 경우 bias와 variance 둘다 줄이긴 힘들다.
5) Bootstrapping
- 학습 데이터 중 일부만 활용하여 모델을 여러개 만들어서 하나의 입력에 대해 각각의 모델들의 예측 값들이 얼마나 일치를 이루는 지 보고 싶을 때 활용.
- 학습 데이터가 고정되어 있을 때, Sub sampling 통해 학습데이터set을 여러개를 만들고 그것을 가지고 여러 모델을 만들어서 하겠다.
6) Bagging and boosting
- Bagging (Bootstrapping aggregating, 앙상블) : Multiple models are being trained with bootstrapping
- Boosting
: Weak learners 들을 sequential 하게 합쳐서 하나의 Strong learner(=Model)을 만든다.

2. Practical Gradient Descent Methods
Gradient Descent Methods
1) Stochastic gradient descent (SGD)
- Single Sample을 통해서만 gradient descent을 계산해서 update
2) Mini-batch gradient descent
- Subset of data을 통해서 gradient descent을 계산해서 update
3) Batch gradient descent
- Whole data(모든 데이터)를 사용해서 gradient descent을 계산하여 update
*) Batch-size Matters
- Large batch -> sharp minimizers 도달
- Small-batch -> flat minimizers 도달
- 실험적인 결과로 Batch사이즈가 적을 수록 (=flat minimum에 도달) 좋다.

- 즉, Flat Minimizer는 Generalization Performance가 높다.
Practical Gradient Descent Methods
1. Stochastic Gradient descent
- 기본적인 Gradient descent
- 문제점, Learning rate를 적절하게 설정하기 어렵다.

2. Momentum (관성)
- Momentum과 현재 Gradient를 합침

3. Nesterov Accelerated Gradient (NAG)
- Gradient를 계산할 때, Lookahead gradient를 계산한다.


4. Adagrad
- NN의 파라미터가 지금까지 얼마나 변해왔는지, 많이 변한 Parameter는 더 적게 변화시키고 별로 안 변한 Parameter는 많이 변화시키고 싶을 때
- 변해왔는지 저장하는 변수 G
- G가 계속 커져 무한대로 수렴하면 결국 학습이 멈춰지는 현상(분모가 0으로 가므로)이 발생

5. Adadelta
- Adagrad의 문제점을 보완
- Learning rate가 없다.

6. RMSprop
- 경험에 의해 발견

7. Adam
- Gradient squares, Momentum

3. Regularization
Generalization을 잘 되게 하고 싶다 -> 학습을 방해 -> 학습 데이터 뿐만 아니라 Test Data에서도 잘 동작하게 하도록 하기 위해서
1. Early Stopping

2. Parameter norm penalty
- 네트워크 파라미터들을 다 제곱하고 더한 값을 줄이자. -> 네트워크 파라미터들을 너무 크게 만들지 말자
(크기 관점에서)

3. Data augmentation
- Data는 많을 수록 성능이 좋아진다.

- 그러나 데이터는 한정적이므로 -> Data augmentation
- 데이터의 Label을 벗어나지 않는 선에서 Data를 변환시킨다.

4. Noise robustness
- 입력 Data에 Noise를 집어 넣는다.
- 단순히 입력에만 Noise 집어넣는게 아니라 Weight들에도 집어넣는다.
5. Label smoothing
- Train 데이터 두개를 뽑아서, 섞어 준다. (Data Augmentation과 비슷)

6. Dropout
- NN의 Weight들 중 몇몇을 0으로 바꾼다. (= 학습에 영향을 주지 않겠다)

7. Batch normalization
- Batch normalization compute the empirical mean and variance independently for each dimension (layers) and normalize.
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 2015
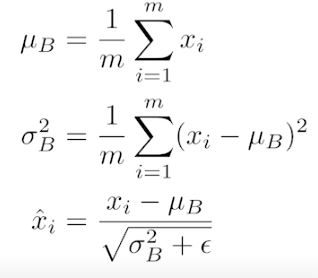
- There are different variances of normalizations

2) CNN
CNN
1. Convolution 연산
- 커널(Kernel)을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조
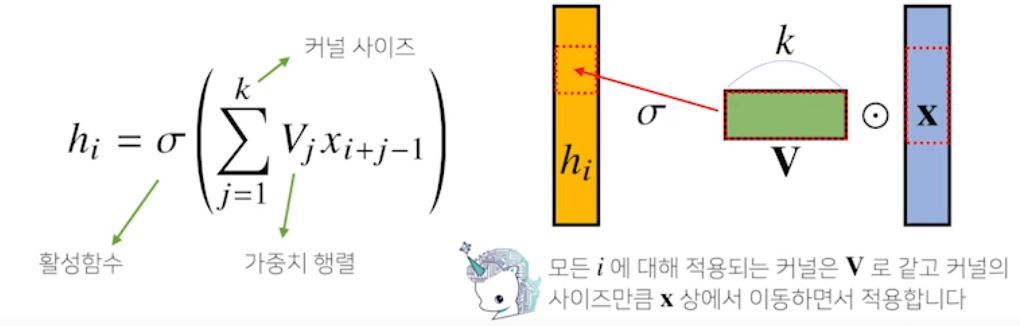
- Convolution 연산의 수학적인 의미는 신호를 커널을 이용해 국소적으로 증폭 or 감소시켜서 정보를 추출 또는 필터링하는 것

- 다양한 차원에서의 Convolution

- 채널이 여러개인 2차원인 경우, Filter도 채널 개수만큼 적용해야한다.


2. Convolution 연산의 역전파
- Convolution 연산은 커널이 모든 입력데이터에 공통으로 적용되므로, 역전파를 계산할 때도 convolution 연산이 나오게 된다.


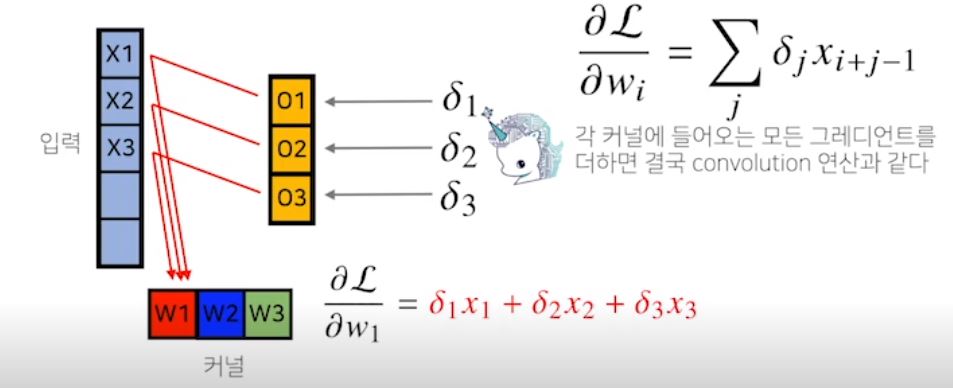
* Filter의 값이 바로 우리가 얻고자하는 가중치 weight
2. 피어 세션
1. 강의 내용에 대한 토의
- Test Data / Validation Data
- 분류 문제에서 cross-validation 적용 시 어떻게 해야 할까?
- 올바르게 cross-validation 하는 법?
- 시계열 데이터의 경우, K Fold
- CNN의 목적
- 커널(필터) 내부 값은 무엇일까? -> 우리가 구할 weight
3. Conclusion
오늘 피어세션에서 많은 의문점과 이해가 안되던 부분을 많이 해소하고 새롭게 알아서 도움이 많이 되었다.
BAT 을 준비하면서도 사실 CNN에 대해 대강만 이해하고 넘어간 부분을 오늘 모두 해소하고 올바른 개념을 바로 잡아놓은것 같아서 관련 자료나 정리내용을 따로 기록을 해놓았다.
또 실습 부분에서 Colab과 구글드라이브를 연동하여 구글드라이브에 데이터셋을 다운받아 압축을 풀어 사용하려 했는데, 압축 푸는 과정만 4~5시간 넘게 걸려 포기를 했다.
모델이 복잡하지않고, 데이터도 기가 단위가 아니므로 단지, 실습과 연습을 해보는 것이 목표이므로 그냥 로컬에서 돌려야겠다..
'부스트캠프 AI Tech > 학습정리' 카테고리의 다른 글
| [Day 14] RNN (0) | 2021.02.04 |
|---|---|
| [Day 13] CNN (0) | 2021.02.03 |
| [Day 11] 딥러닝 기초 (0) | 2021.02.01 |
| [Day 10] 시각화 / 통계학 (0) | 2021.01.29 |
| [Day 09] Pandas / 통계학 (0) | 2021.01.28 |
- Total
- Today
- Yesterday
- 알고리즘
- 프로그래머스
- DACON
- NLP 구현
- 부스트캠프 AI Tech
- 백트래킹
- 다이나믹프로그래밍
- P-Stage
- 공공데이터
- AI 프로젝트
- Vision AI 경진대회
- Unet
- 이분탐색
- DeepLearning
- 네트워킹데이
- C++
- 브루트포스
- 백준
- Data Handling
- 데이터연습
- cnn
- pandas
- ResNet
- python
- 그리디
- 코딩테스트
- 데이터핸들링
- dfs
- Unet 구현
- 동적계획법
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |