
티스토리 뷰
[Day 13] CNN
1. 강의 복습 내용
CNN
1. Convolution
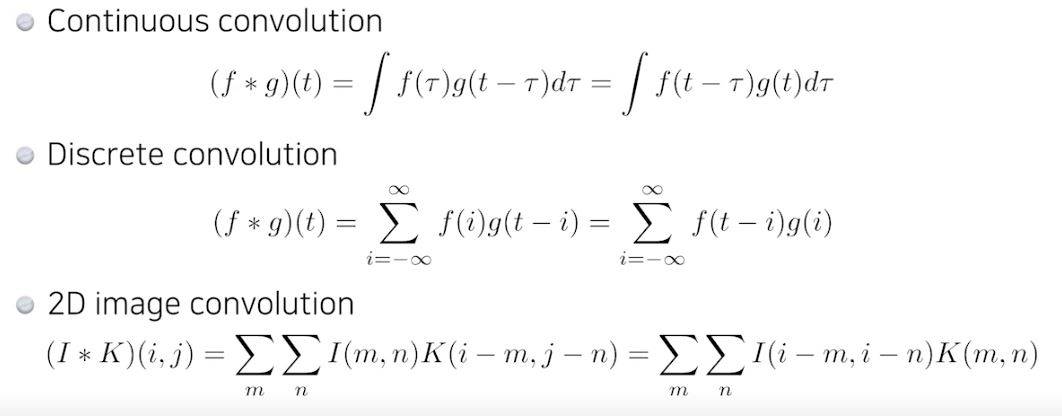

- RGB Image Convolution
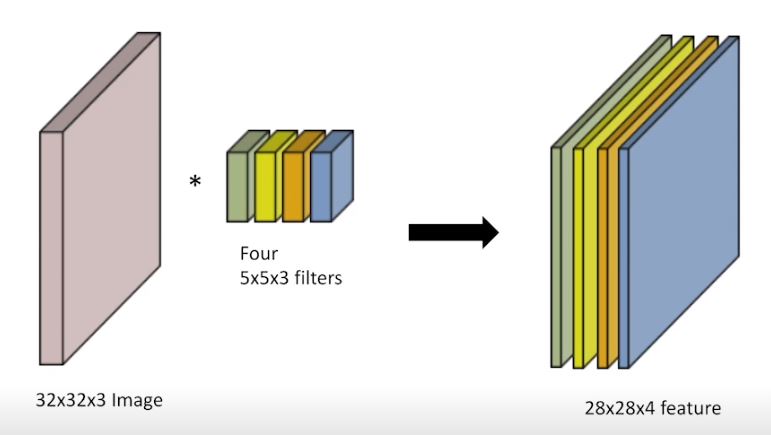
- input 의 채널과 filter의 채널은 같아야하고 이때 1개의 feature를 얻을 수 있다.
- 따라서 input의 채널 수와 output의 채널 수를 알면 몇개의 filter가 필요한지 알 수 있다.
- 이를 토대로 Filter들의 Parameter 개수도 도출해낼 수 있다.
2. Convolution Neural Networks

- Convolution & pooling layers : feature extraction
- Fully Connected Layer : 최종적으로 원하는 결과값을 만들어줌
(최근 들어서, 점점 없어지거나 최소화시키는 추세 -> Parameter 숫자에 dependent)
1) Stride : Filter로 픽셀을 어느 정도의 간격으로 찍어 볼 지 정하는 간격
2) Padding : Boundary 정보가 버려지는 상황을 방지하기 위해서 사용한다.
3. 1x1 Convolution
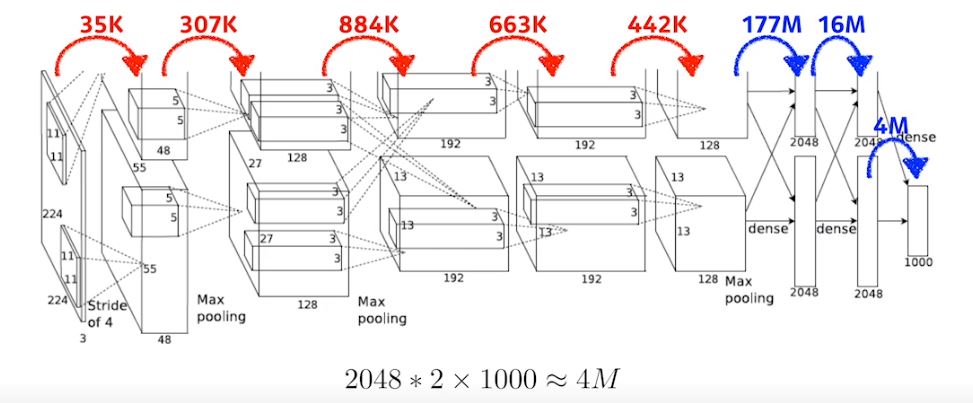
- NN의 성능을 올리기 위해서는 Parameter의 수를 줄이는 것이 중요하다.
- 하지만, Parameter 수가 Fully Connected Layer에서 급격히 증가하기 때문에 뒷단에 있는 Fully Connected Layer를 줄이고 앞단에 Convolution Layer를 깊게 쌓는 것이 현재 Trend 이다.
- 따라서 이를 위해 사용하는것이 1x1 Convolution
Why?
1) 채널을 줄일 수 있다. -> Parameter 수를 줄일 수 있음 (Dimension(=Channel) reduction)
2) Convolution Layer를 깊게 쌓으면서 동시에 Parameter 수를 줄이는 것
1. CNN 모델들의 발전 추세
- 결국 네트워크의 깊이는 점점 깊어지고, Parameters의 수는 줄어든다.
1) AlexNet
- 최초로 Deep Learning을 이용하여 ILSVRC에서 수상.
2) VGGNet
- 3x3 Convolution을 이용하여 Receptive field는 유지하면서 더 깊은 네트워크를 구성.
3) GoogLeNet
- Inception blocks 을 제안.
4) ResNet
- Residual connection(Skip connection)이라는 구조를 제안.
- h(x) = f(x) + x 의 구조
5) DenseNet
- Resnet과 비슷한 아이디어지만 Addition이 아닌 Concatenation을 적용한 CNN.
2. Semantic Segmentation
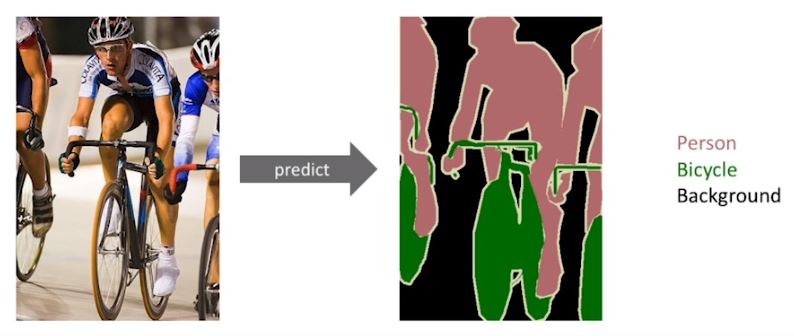
- 어떤 이미지가 있을 때, 각 이미지를 픽셀 마다 분류하는 문제
- 즉, 이미지의 모든 픽셀이 어떤 Label에 속하는 지 보고 싶을 때
- 자율 주행에 많이 사용
1) Fully Convolutional Network
- Dense Layer를 없앤다.
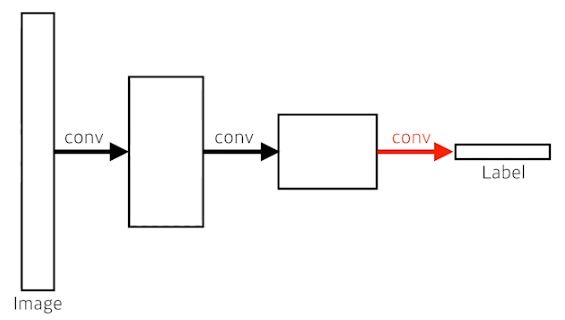

- 결국 결과는 같은데 왜 이렇게 할까? -> Dense Layer의 경우엔 input image의 크기가 바뀌면 영향을 받는다.
- Transforming fully connected layers into convolution layers enables a classification net to output a heat map
- While FCN can run with inputs of any size, the output dimensions are typically reduced by subsampling
- So we need a way to connect the coarse output to the dense pixels.
2) Deconvolution (conv transpose)
- 직관적으로 Convolution의 역연산
- 그러나 역연산이라고 역으로 복원한다는 것을 생각하면 안된다.
3) Detection
- Bounding Box를 찾는 문제
1. R-CNN
- 브루트포스 (Bounding Box 2000개) -> 느리다
2. SPPNet
- R-CNN에서 2000개를 모두 conv layers를 통과시키는 것에서 한번만 통과시키고 Tensor로 뽑아옴

3. Fast R-CNN

4. Faster R-CNN
- Bounding Box를 뽑아내는 Region Proposal 과정도 학습을 통해 뽑아내자 라는 idea

- Region Proposal Network


- 54개의 Features channel 도출
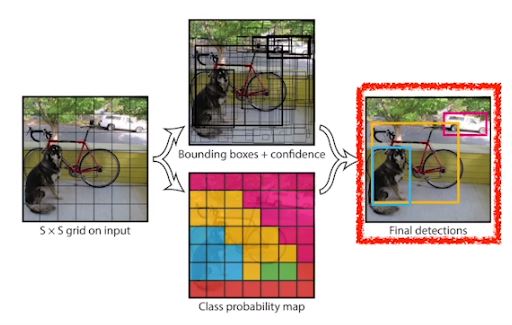
5. YOLO
- 이미지 한장에서 바로 Output 도출 (때문에 빠르다 -> Bounding Box 분류 작업이 없으므로)
- 이미지를 SxS Grid로 나눈다.
2. 피어 세션
1. 강의 내용에 대한 토의
- Feature의 개수(필터의 개수)는 역시 모델 설계자의 경험에서 나오는 수치인가? (OUTPUT 제외)
- Parameter의 수를 줄이면서도 더 딥하게 층을 쌓는 모델이 추세인데, 최적의 Parameter 개수란 무엇일까?
- 모델의 Parameter 수는 모델의 표현력이라 볼 수 있다. -> Parameter수, 즉 모델의 표현력이 과하면 Overfitting 위험성
- 모델의 복잡도, GPU의 성능과 개수에 따라 최적의 Parameter수도 변할까?
2. 오늘 간략하게 소개한 모델 논문들 Overview
3. 다음주 휴강을 대비한 피어세션 플랜
- 이미지 분류 주제 정해서 각각 CNN 모델을 만들고 코드리뷰&성능 리뷰 계획
3. Conclusion
구글 드라이브에 데이터셋을 올리고 실습하는 것이 너무 느리고 비효율적인 것 같다. 다른 방법을 찾아봐야할 것 같다. (학습용 컴퓨터을 구축해 SSH 서버를 열고 연결해서 하는 방향?)
Notmnist 데이터셋을 구글 드라이브에 설치하는 것에만 6시간이 걸림

'부스트캠프 AI Tech > 학습정리' 카테고리의 다른 글
| [Day 15] Generative Models (0) | 2021.02.05 |
|---|---|
| [Day 14] RNN (0) | 2021.02.04 |
| [Day 12] 최적화 (0) | 2021.02.02 |
| [Day 11] 딥러닝 기초 (0) | 2021.02.01 |
| [Day 10] 시각화 / 통계학 (0) | 2021.01.29 |
- Total
- Today
- Yesterday
- 백트래킹
- Data Handling
- python
- pandas
- 백준
- ResNet
- 부스트캠프 AI Tech
- cnn
- NLP 구현
- 이분탐색
- DACON
- 그리디
- 공공데이터
- C++
- 다이나믹프로그래밍
- 코딩테스트
- 동적계획법
- 브루트포스
- Vision AI 경진대회
- dfs
- AI 프로젝트
- 프로그래머스
- 네트워킹데이
- 알고리즘
- Unet
- DeepLearning
- P-Stage
- Unet 구현
- 데이터핸들링
- 데이터연습
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |