
티스토리 뷰
[Day 08] Pandas / 딥러닝 학습방법 이해하기
1. 강의 복습 내용
1) Pandas
Pandas
- 구조화된 데이터의 처리를 지원하는 Python 라이브러리
- Panel data -> pandas
- 고성능 array 계산 라이브러리인 numpy와 통합하여 강력한 '스프레드시트' 처리 기능을 제공
- 인덱싱, 연산용 함수, 전처리 함수등을 제공
- 데이터 처리 및 통계 분석을 위해 사용
1. 데이터 구조 정의

2. 데이터 로딩
data_url='URL' # Data URL
df_datatable=pd.read_csv(data_url, sep='\s+', header=None)
# csv 타입 데이터 로드, separate는 빈공간(space)으로 지정, Column은 없다(None)3. Series
- Column vector를 표현하는 Object
- DataFrame 중 하나의 Column에 해당하는 데이터의 모음


list_data=[1,2,3,4,5]
list_name=["a","b","c","d","e"]
example_obj=Series(data=list_data,index=list_name)
example_obj
'''
a 1
b 2
c 3
d 4
e 5
dtype: int64
'''# Dict type도 가능
dict_data={"a":1,"b":2,"c":3,"d":4}
example_two=Series(data=dict_data)
example_two
'''
a 1
b 2
c 3
d 4
dtype: int64
'''example_two['a'] # data index에 접근
example_two['b']=29 # data index에 값 할당하기- 인덱스 값에 dict타입처럼 넣을 수 있고, value도 변경가능하다.
example_obj.values # 값 리스트만 추출
example_obj.index # index 리스트만 추출
example_obj.name = "Number"
example_obj.index.name="alphabet" # DATA에 대한 정보를 저장dict_data_1={"a":1,"b":2,"c":3,"d":4,"e":5}
indexes={"a","b","c","d","e","f","g","h"}
obj_1=Series(dict_data_1,index=indexes) # 인덱스 값을 기준으로 Series 생성
obj_1
'''
g NaN
f NaN
d 4.0
c 3.0
h NaN
a 1.0
e 5.0
b 2.0
dtype: float64
'''4. Dataframe
- Data Table 전체를 포함하는 Object
- Series를 모아서 만든 Data Table => 기본 2차원

+) 각각의 데이터 type이 다를 수 있다.
* Dataframe indexing
1) loc - index location
2) iloc - index position
*) 둘의 차이점
loc은 index(=label) 이름, iloc은 index number(= integer position)
* Dataframe Handling
- boolean index로도 값을 넣을수 있다.
- values => array type으로 출력
- to_csv() => csv로 변환
- drop & del
| drop | del |
| 원본이 남아있다. | 메모리에서 삭제-> 원본에서도 제거 |
- Selection with column names

- 한개의 column 추출 -> Series 형태
- 1개 이상 column 추출 -> List(리스트) 형태로 담아서 추출해야함
5. Series Operation
s1 = Series(range(1,6), index=list("abcde"))
s1
'''
a 1
b 2
c 3
d 4
e 5
dtype: int64
'''- index 기준으로 연산수행
- 겹치는 index가 없으면 NaN값 return
6. Dataframe Operation

- Dataframe은 column과 index를 모두 고려한다
- Add operation을 사용하면 NaN값을 0으로 변환할 수 있다.
(Operation types: add, sub, div, mul)
7. Series + Dataframe
- '+' 연산은 일어나지 않는다.

8. Map for series
- pandas의 series type의 데이터에도 map 함수 사용가능
- function 대신 dict, sequence형 자료등으로 대체 가능

- Replace function
: Map 함수의 기능중 데이터 변환 기능만 담당
: 데이터 변환시 많이 사용하는 함수
*) inplace=True를 해줘야 데이터 변환 결과를 원본에 적용시킨다.
- Apply for dataframe
: map과 달리, series 전체(column)에 해당 함수를 적용
: 입력 값이 series 데이터로 입력 받아 handling 가능
: 내장 연산 함수를 사용해도 똑같은 효과를 거둘 수 있다.
ex) mean, std 등
: scalar 값 이외에 series값의 반환도 가능
- Applymap
: series 단위가 아닌 element 단위로 함수를 적용
: series 단위에 apply를 적용 시킬 때와 Map이랑 같은 효과
- 기본적으로 column 단위로 적용시킨다
9. Pandas built-in functions
1) describe
- Numeric type 데이터의 요약 정보를 보여줌

2) unique
- Series data의 유일한 값의 list를 반환
3) sum
- 기본적인 column 또는 row 값의 연산
- sub, mean, min, max, count, median, mad, var 등
4) isnull
- column 또는 row 값의 NaN (null) 값의 index를 반환함
ex) df.isnull().sum() #Null인 값의 합
5) sort_values
- column 값을 기준으로 데이터를 sorting
6) Correlation & Covariance
- 상관계수와 공분산을 구하는 함수
- corr, cov, corrwith
2) 딥러닝 학습방법 이해하기
딥러닝 학습방법 이해하기
1. 선형모델


- d개의 변수로 p개의 선형모델을 만들어 p개의 잠재변수를 설명하는 모델로 볼 수 있다.
- 선의 개수는 총 d*p가 필요하며, 이는 W행렬(d*p)와 같으므로 선의 의미는 W행렬로 볼 수 있다.
2. 비선형모델
1) SOFTMAX(소프트맥스) 함수
- 분류 문제를 풀 때, 선형모델과 소프트맥스 함수를 결합하여 예측
- 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산(=함수)

- 이를 사용하면 주어진 데이터가 어떤 특정 CLASS에 속하는지 알 수 있다.
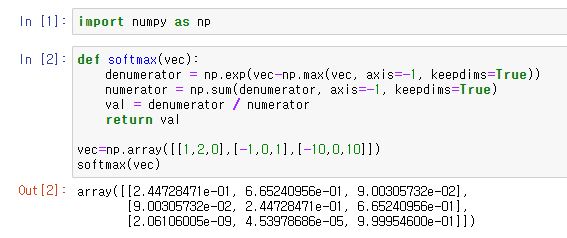
- 위의 출력 결과와 같이 SOFTMAX 함수를 통해 벡터를 확률벡터로 변환할 수 있다.
- 그러나 추론을 할때, 출력 값에서 가장 최댓값을 가지는 주소만 1로 출력하는 one-hot 벡터를 사용한다.
- 따라서 학습할때는 SOFTMAX를 쓰지만, 이런식으로 추론할 때는 one-hot 벡터로 만드는 함수로 충분하다.
2) 활성함수
- 활성함수를 쓰지 않으면 딥러닝은 선형모형과 차이가 없다. -> wx+b는 여러층으로 구성해도 하나의 층으로 표현 가능하기 때문
- 시그모이드(sigmoid) 함수나 tanh 함수는 전통적으로 많이 쓰이던 활성함수
- 딥러닝에선 ReLU 함수를 많이 쓰고 있다.

*) 소프트맥스와 활성함수의 차이
- 출력물의 모든것을 고려한다면, 활성함수는 오직 해당주소에 있는 값만 가지고 계산하기 때문에, 벡터를 인풋으로 받지않고 하나의 실수값을 입력받는다.
- 이 활성함수를 이용하여, 딥러닝에서는 선형모델로 나온 출력물을 비선형모델로 변환을 시킬 수 있다.
(이렇게 변형시킨 벡터를 잠재벡터, 히든벡터 -> 뉴런 , 뉴런으로 이루어진 모델->신경망(=뉴럴네트워크))
3) 신경망
- 신경망은 선형모델과 활성함수를 합성한 함수
- 다층(Multi-layer) 퍼셉트론(MLP)은 신경망이 여러층 합성된 함수

*) 층을 여러개 쌓는 이유
- 이론적으로는 2층 신경망으로도 임의의 연속함수를 근사할 수 있다.
- 하지만 층이 깊을수록 목적함수를 근사하는데 필요한 뉴런(노드)의 숫자가 훨씬 빨리 줄어들어 좀 더 효율적으로 학습이 가능하다.

BUT) 층이 깊다고 해서 복잡한 함수를 근사를 할 수 있지만, 최적화가 더 쉽지는 않다.
3. 딥러닝 학습원리 : 역전파 알고리즘
- 딥러닝은 역전파(Backpropagation) 알고리즘을 이용하여 각 층에 사용된 패러미터를 학습한다.

- 딥러닝의 경우, 여러층으로 구성되어있기 때문에 한번에 gradient vector를 계산할수 없으므로 역순으로 순차적으로 계산해줘야한다.
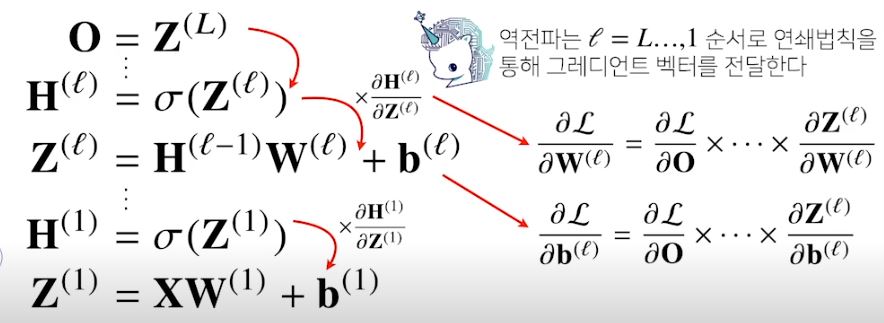
- 출력 층에서부터 시작해서 입력층까지 '연쇄법칙(Chain Rule)'을 통해서 계산
- 즉, 역전파 알고리즘은 합성함수의 미분법인 연쇄법칙(Chain-Rule) 기반 자동미분(Auto-Differentiation)을 사용
2. 피어 세션
1. 강의내용에 대한 토의
- 활성함수의 역할
- SOFTMAX 함수가 사용되는 이유
- SOFTMAX 함수의 결과값이 분류 모델의 학습에 어떻게 사용될까?
- 역전파 알고리즘으로 학습할 때 bais는 어떻게 되는것인가?
- 신경망에서 노드(뉴런)의 갯수의 의미
- SOFTMAX 함수는 왜 지수함수로 이루어져있나? 2^x 함수로도 가능했을텐데? 이유가 뭘까?
등 다양한 토론 진행
3. Conclusion
오늘은 강의의 내용도 많고 중요하게 다룰 내용이 많아서 피어세션에서 햇갈리는 점, 모르는 점, 토의해볼만한 점에 대해 얘기를 나누다보니 시간이 훌쩍 가버렸다.
강의만 들으면 몰랐을법한 내용이나 애매하게 알고있던 내용을 토의를 하면서 새롭게 배우고 잘못 이해했던 부분을 바로 잡으며 유익했던 것 같았다.
가장 기억에 남았던 토의 내용은 소프트함수가 지수함수로 이루어져있는 것은, 가장 큰 이유가 미분하기 쉬워서 라고 한다.
간단 명료하게 다 수긍이 되는 명쾌한 답변이였다.
'부스트캠프 AI Tech > 학습정리' 카테고리의 다른 글
| [Day 10] 시각화 / 통계학 (0) | 2021.01.29 |
|---|---|
| [Day 09] Pandas / 통계학 (0) | 2021.01.28 |
| [Day 07] 경사하강법 (0) | 2021.01.26 |
| [Day 06] Numpy / 벡터 / 행렬 (0) | 2021.01.25 |
| [Day 05] 파이썬으로 데이터 다루기 (0) | 2021.01.22 |
- Total
- Today
- Yesterday
- Vision AI 경진대회
- cnn
- python
- 프로그래머스
- 부스트캠프 AI Tech
- Data Handling
- ResNet
- 브루트포스
- 공공데이터
- 백트래킹
- DeepLearning
- AI 프로젝트
- dfs
- Unet
- 데이터연습
- 다이나믹프로그래밍
- 데이터핸들링
- C++
- NLP 구현
- DACON
- P-Stage
- 동적계획법
- 알고리즘
- 네트워킹데이
- pandas
- 이분탐색
- 백준
- Unet 구현
- 코딩테스트
- 그리디
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |