
티스토리 뷰
[Day 16] NLP (자연어 처리) - 1
1. 강의 복습 내용
NLP (자연어 처리) - 1
1. Bag-of-Words (BOW)
- 빈도수 기반의 단어 표현 방법
- 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중
- BOW를 만드는 방법
1) 각 단어에 고유한 정수 인덱스 부여
2) 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터 생성
2. NaiveBayes Classifier
- 텍스트 분류를 위해 전통적으로 사용되는 분류기 (=나이브 베이즈 분류기)
- 베이즈 정리와 BOW를 이용하여 텍스트 분류를 수행
- 입력 Text에서 단, 하나의 단어라도 훈련 Text에 없었다면 확률 전체가 0이 되어버린다.
- 이를 방지하기 위해서 각 단어에 대한 확률의 분모, 분자에 전부 숫자를 더해서 분자가 0이 되는 것을 방지하는 라플라스 스무딩을 사용 (=K)


- NaiveBayes Classifier 적용해보기
(DACON 청와대 청원 : 청원의 주제가 무엇일까?)
www.dacon.io/competitions/open/235597/overview/
[문자] 청와대 청원 : 청원의 주제가 무엇일까?
출처 : DACON - Data Science Competition
dacon.io

- 간단한 알고리즘 임에도 불구하고 준수한 성능을 보여준다.
소스코드 : github.com/hunmin-hub/DL_Tutorial/tree/main/DACON_Bluehouse
hunmin-hub/DL_Tutorial
DeepLearning Tutorial. Contribute to hunmin-hub/DL_Tutorial development by creating an account on GitHub.
github.com
3. Word Embedding (워드 임베딩)
- 자연어를 컴퓨터가 이해하고, 효율적으로 처리하게 하기 위해서는 컴퓨터가 이해할 수 있도록 자연어를 적절히 변환할 필요가 있다.
- 단어를 표현하는 방법에 따라서 자연어 처리의 성능이 크게 달라지기 때문에, 이에 많은 연구가 있었고 다양한 방법들이 알려져 있다.
- 즉, 단어를 벡터로 표현하는 방법을 Word Embedding (워드 임베딩)이라고 하며, 이 벡터를 워드 임베딩 과정을 통해 나온 결과를 Embedding Vector (임베딩 벡터)라고 한다.
4. Word2Vec (워드투벡터)
- '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다' 라는 가정 -> Sliding Window
- 원-핫 벡터를 단어간의 유사도를 계산할 수 있는 벡터로 변환 (Embedding) -> 임의의 m 차원 벡터
1) CBOW (Continuous Bag Of Words)
- 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법 (Output -> 중심단어)
- Sliding Window의 크기가 n이면, 입력에 들어가는 벡터의 수는 2n개
- 입력층, 투사층(M차원), 출력층으로 구성 ( 가중치행렬은 총 2개)
- 단어의 개수 V, [NxV] * [VxM] -> [NxM] * [MxV] -> [NxV]
- 두 가중치 행렬 W, W'가 학습이 다 되었다면 M차원의 크기를 갖는 W의 행이나 W'의 열로부터 어떤 것을 임베딩 벡터로 사용할지를 결정 (두 가중치 행렬의 평균을 사용하기도 함)

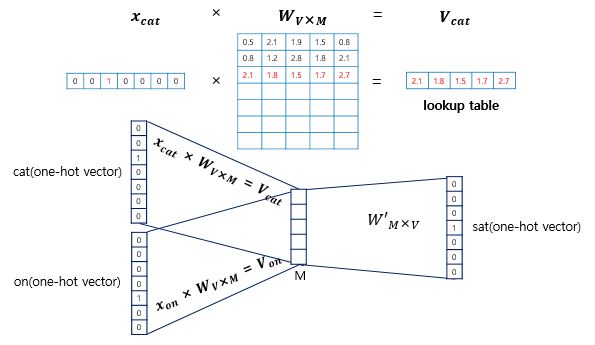


2) Skip-Gram
- 중심 단어에서 주변 단어들을 예측
- 중심 단어에 대해서 주변 단어를 예측하므로, 투사층에서 벡터들의 평균을 구하는 과정이 없다.
- 전반적으로 CBOW보다 성능이 좋다.

5. GloVe (글로브)

- GloVe (글로브)는 카운트 기반과 예측 기반 모두를 사용하는 방법론
참조 : https://wikidocs.net/book/2155
2. 피어 세션
1. 강의 내용에 대한 토의
- NaiveBayes Classifier는 Train Data 전체를 사용하는 알고리즘, 하지만 데이터가 너무 많아서 BATCH를 통한 입력을 받아야 할때는 어떻게 계산해야하나?
- NaiveBayes Classifier 메모리 리소스적 한계?
- Word2Vec과 GloVe의 단점
1) Word2Vec : Sliding Window의 한계
2) GloVe : 계산 복잡성이 높고 메모리를 많이 필요로 함.
+ 반대 단어 쌍을 분리하는 방법. 예를 들어, "양호한"및 "나쁜"은 일반적으로 벡터 공간에서 서로 매우 가깝게 위치하므로 정서 분석과 같은 NLP 작업에서 단어 벡터의 성능이 제한(Word2Vec도 동일한 문제를 안고 있음)
eda-ai-lab.tistory.com/428
2. 휴강 주간 동안 팀 실습 ( CNN 분류모델 )
- 코드 리뷰
- 구성한 모델 구조 소개
3. Conclusion
휴강 주간 동안 여러 모델들을 구현해보고 실습해본 것들이 많이 도움이 되는 것 같다.
PyTorch에 익숙해지기 전에는, 이론적인 부분은 이해해도 코드로 그려지기 쉽지 않았는데 코드로 같이 이해할 수 있어서 실습하는 재미가 더 해지는 것 같고 적용하는 재미도 생기는 것 같다.
앞으로 더 열심히 해야겠다.
'부스트캠프 AI Tech > 학습정리' 카테고리의 다른 글
| [Day 18] NLP (자연어 처리) - 3 (0) | 2021.02.17 |
|---|---|
| [Day 17] NLP (자연어 처리) - 2 (0) | 2021.02.16 |
| [Day 15] Generative Models (0) | 2021.02.05 |
| [Day 14] RNN (0) | 2021.02.04 |
| [Day 13] CNN (0) | 2021.02.03 |
- Total
- Today
- Yesterday
- ResNet
- DeepLearning
- 다이나믹프로그래밍
- 프로그래머스
- 브루트포스
- 공공데이터
- 데이터핸들링
- Unet 구현
- 알고리즘
- dfs
- C++
- 그리디
- python
- pandas
- Vision AI 경진대회
- 네트워킹데이
- 코딩테스트
- AI 프로젝트
- cnn
- NLP 구현
- 백준
- Unet
- 이분탐색
- 백트래킹
- P-Stage
- DACON
- 동적계획법
- 데이터연습
- Data Handling
- 부스트캠프 AI Tech
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |