
티스토리 뷰
[Day 18] NLP (자연어 처리) - 3
1. 강의 복습 내용
NLP (자연어 처리) - 3
1. Sequence-to-Sequence (seq2seq)
- 입력 시퀀스로부터 다른 도메인의 시퀀스를 출력 (Many To Many)
- 번역기에서 대표적으로 사용되는 모델
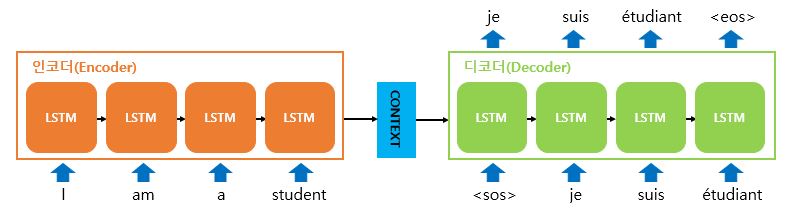
- 인코더와 디코더의 내부는 사실 두개의 RNN 아키텍쳐
- 입력 시퀀스를 받는 RNN 셀을 '인코더'
- 출력 시퀀스를 출력하는 RNN 셀을 '디코더'
- 인코더는 모든 시퀀스를 입력 받은 후 마지막 시점의 은닉 상태를 디코더로 넘겨준다. (Thought Vector)
2. seq2seq Model with Attention
- RNN에 기반한 seq2seq모델의 한계
- 하나의 고정된 크기의 Thought Vector(=CONTEXT)에 모든 정보를 압축해서 넣어야 하기 때문에 정보 손실이 발생
- RNN의 고질적인 문제인 Gradient Vanishing(=기울기 소실) 발생
- 따라서 이러한 한계를 보완하기 위해 등장한 기법인 Attention
1) Attention
- 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한번 참고한다는 아이디어
- 그러나 전체 입력 문장을 모두 다 동일한 비중으로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(Attention)해서 본다. -> Softmax
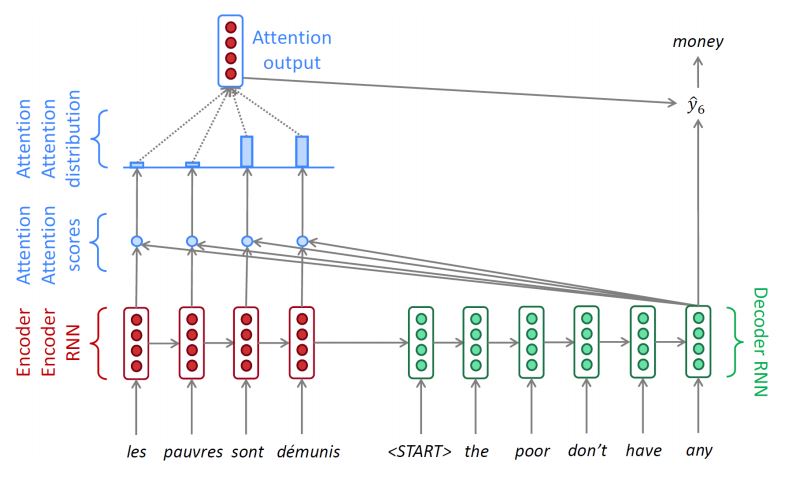
2) Dot-Product Attention
1) 어탠션 스코어 (Attention Score)를 구한다. -> 스칼라 값
- 현재 디코더 시점 t에서의 단어를 예측하기 위해, 인코더의 모든 은닉 상태 각각이 디코더의 현시점 은닉 상태와 얼마나 유사한지를 판단하는 값
- 현재 디코더 시점 t에서의 은닉 상태 값을 전치하여 각 인코더의 은닉 상태와 내적을 수행한다. -> 스칼라 값
2) SOFTMAX (소프트맥스) 함수를 통해 어텐션 분포 (Attention Distribution)을 구한다.
- 여기서 얻어진 각각의 값은 어텐션 가중치 (Attention Weight)
3) 각 인코더의 어텐션 가중치와 은닉 상태를 가중합하여 어텐션 값 (Attention Value)을 구한다.
- 각 인코더의 은닉 상태와 어텐션 가중치들을 곱하고 최종적으로 모두 더한다.
- 이러한 값은 인코더의 문맥을 포함하고 있다고 하여 Context Vector라고도 불린다.
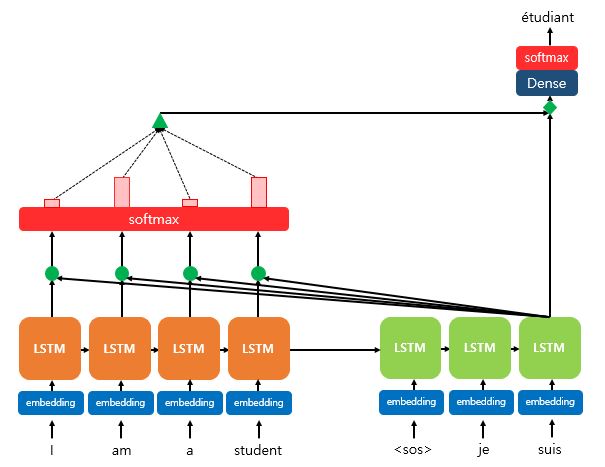
4) 어텐션 값과 디코더의 t 시점의 은닉 상태를 연결한다. (Concatenate)
- 하나의 벡터로 만드는 작업을 수행
5) 출력층 연산의 입력이 되는 값을 계산한다.
- Step 4에서 얻은 벡터를 출력으로 보내기 전 신경망을 한번 더 거친다.
- 신경망을 거쳐 나온 새로운 벡터를 다음 시점 t의 디코더 입력과 출력층의 입력으로 들어간다.
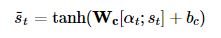
6) 출력층에 들어온 벡터를 통해 예측 벡터를 얻는다.
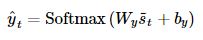
3) 다양한 종류의 Attention

3. Text 생성을 위한 Decoder
1) Greedy Decoding
- 현재 시점 t의 예측 단어 중 가장 확률이 높은 것만을 선택하는 방법
- 그러나, 잘못 예측한다면 다음부터의 예측 값들도 모두 잘못될 확률이 크며 돌이킬 방법이 없다.
2) Exhaustive Search
- 브루트포스 개념의 선택 방법
- 모든 시점에서 예측할 수 있는 단어들을 모두 조합하여 최선의 확률 시퀀스를 뽑아준다.
- O(V^T)의 시간복잡도 (V : Vocab size, T : 시퀀스 길이) -> 시간이 너무 오래 걸린다.
3) Beam Search
- 각 시점 t에서 빔의 size (=k) 만큼의 경우들만 골라 탐색하는 방법
- Greedy Decoding의 경우는 빔이 1인 Beam Search와 같다.

* Training 과정에서도 사용되는 것인가?
- Train 과정에서는 정해진 label이 있으므로 Softmax로 뽑혀진 값들 중에서 Greedy 탐색을 한다고 볼 수 있다.
- 하지만 Train 과정에서도 Beam Search를 적용하는 경우도 있으며 이 경우 일반적인 seq2seq Model의 손실함수가 아닌 다른 손실함수를 사용해야 한다.
4. BLEU Score
- 기계번역을 통해 만들어진 text의 퀄리티를 평가하는 방법
- 사람이 정하는 Reference와 비교하여 평가
- min 부분은 예측 길이를 보정해주는 부분 (Brevity Penalty)
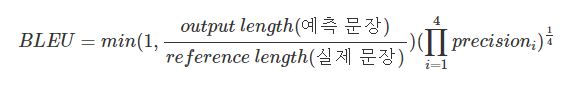
- N-gram을 통하여 각 순서쌍들이 얼마나 겹치는 지 측정 (precision)

참조
https://donghwa-kim.github.io/BLEU.html
https://velog.io/@nawnoes/%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-Beam-Search
https://wikidocs.net/24996
2. 피어 세션
1. 강의 내용에 대한 토의
1) seq2seq모델이 아닌 다른 모델에서의 Attention 활용법
2) Attention의 역할은 무엇일까?
3) Beam Search는 Training 과정에서도 사용되는가?
4) BLEU 의 단점
3. Conclusion
"Attention is All you need" 문구처럼 Attention을 좀 더 잘 이해해서 잘 활용해보고 싶다.
추후에 배울 transformer에도 Attention이 사용되기 때문에, 확실히 이해하고 넘어가야겠다.
실습 관련
1. 버켓팅을 간단하게 해주는 함수 torchtext.data.BucketIterator
2. RNN 모델에 입력차원을 (1,0) 전치하여 넘기는 이유
왜냐면 RNN은 sequential한 관계를 학습하는 모델이기 때문입니다. Batch processing을 위해선 서로 다른 데이터를 병렬 계산하는데 각 time step의 단어는 앞선 단어의 관계를 보고 그 다음 단어의 정보를 학습해야 하기 때문에 병렬 연산이 안 됩니다. 그래서 서로 다른 문장 내 같은 time step의 단어를 한꺼번에 묶어서 batch 계산을 하고 그 다음 단어로 넘어가기 때문에 column으로 묶어서 들어가는 것으로 보여집니다.
'부스트캠프 AI Tech > 학습정리' 카테고리의 다른 글
| [Day 20] Self-supervised Pre-training Models (0) | 2021.02.19 |
|---|---|
| [Day 19] Transformer (0) | 2021.02.18 |
| [Day 17] NLP (자연어 처리) - 2 (0) | 2021.02.16 |
| [Day 16] NLP (자연어 처리) - 1 (0) | 2021.02.15 |
| [Day 15] Generative Models (0) | 2021.02.05 |
- Total
- Today
- Yesterday
- cnn
- 동적계획법
- 데이터연습
- 코딩테스트
- dfs
- 부스트캠프 AI Tech
- DACON
- 백트래킹
- DeepLearning
- Unet
- C++
- python
- AI 프로젝트
- 그리디
- 브루트포스
- ResNet
- pandas
- Unet 구현
- 데이터핸들링
- Vision AI 경진대회
- 이분탐색
- 네트워킹데이
- Data Handling
- 알고리즘
- NLP 구현
- 공공데이터
- 프로그래머스
- 다이나믹프로그래밍
- 백준
- P-Stage
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |