
티스토리 뷰
[Day 17] NLP (자연어 처리) - 2
1. 강의 복습 내용
NLP (자연어 처리) - 2
1. RNN (Recurrent Neural Network)
- 시퀀스 모델
- 입력과 출력을 시퀀스 단위로 처리하는 모델
- 시퀀스의 길이에 상관없이 input과 output을 처리할 수 있다.
- 은닉층의 노드에서 활성화 함수를 통해 나온 결과값들을 출력층 방향으로 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징을 가짐
- 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드를 셀(Cell) 이라고 한다
- 은닉층의 셀은 각각의 시점(time step)에서 바로 이전 시점에서의 은닉층의 셀에서 나온 값을 자신의 입력으로 활용
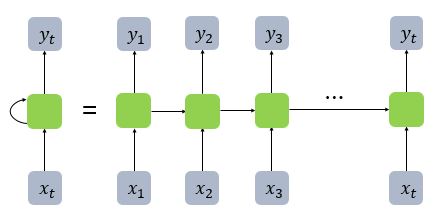

- RNN 수식과 차원 계산
 |
 |
 |
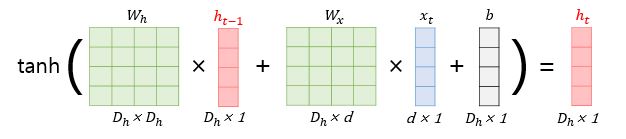 |
* 각각의 가중치들은 모든 시점에서 값을 동일하게 공유한다
* 하지만, RNN Layer가 2개 이상이면 각각의 Layer에서의 가중치는 서로 다르다.
- 양방향 RNN (Bidirectional Recurrent Nerual Network)
양방향 RNN은 시점 t에서의 출력값을 예측할 때 이전 시점의 데이터 뿐만 아니라, 이후 데이터로도 예측할 수 있다는 아이디어에 기반
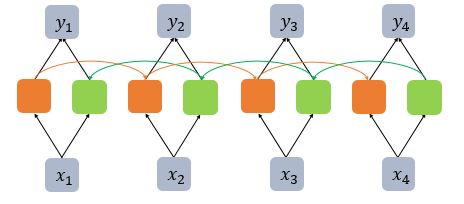
단방향은 하나의 셀을 이용했다면, 양방향은 두개의 셀을 이용하여 하나의 출력값을 예측한다.
- RNN의 한계
RNN은 비교적 짧은 시퀀스에 대해서만 효과를 보인다.
시점이 길어질수록 (=시퀀스가 긴 데이터일수록) 앞의 정보를 충분히 반영하지 못한다. (장기의존성 문제)
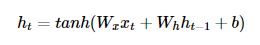
수식처럼 tanh과 같은 활성함수를 사용하게 되면, 몇 time step만 거쳐도 gradient가 0으로 수렴할 수 있다.
ReLU를 사용하는 방법도 있지만, gradient exploding(값이 계속 커져 제어할 수 없을 정도에 도달함)에 이를 수 있다. 물론 gradient clipping과 같은 기법으로 처리 할 수 있지만, gradient 값들이 1보다 작다면 계속된 곱연산으로 인해 gradient vanishing 문제가 치명적이다.
2. LSTM
- RNN의 한계(장기의존성 문제)를 보완하기 위한 다양한 RNN의 변형중 하나
- LSTM은 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정함
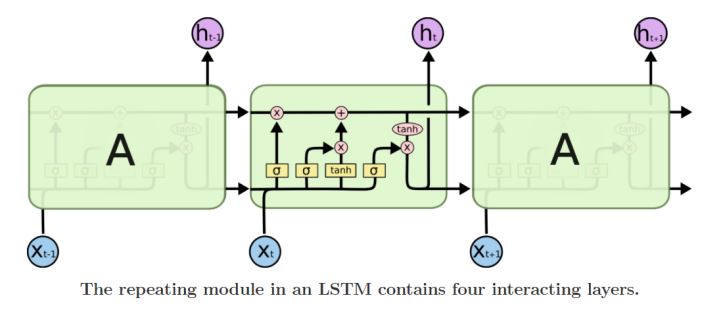
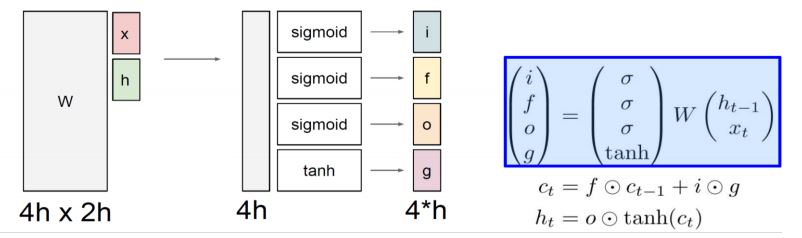
1. 입력 게이트
- 현재 정보를 기억하기 위한 게이트
- 각각 현재 시점 t의 x값과 이전 시점의 출력 값(은닉 상태)이 가중치와 곱해진 후 더하여 sigmoid와 tanh 함수를 지난다.
- 시그모이드 함수를 지난 값은 0~1의 값을 가지고, tanh함수를 지난 값은 -1~1 값을 가진 두개의 값을 얻는다.
2. 삭제 게이트
- 기억을 삭제하기 위한 게이트
- 현재 시점t의 x값과 t-1의 출력 값이 시그모이드 함수를 지나 0~1의 값을 지니게 된다.
- 이 값은 삭제 과정을 거친 정보의 양을 뜻한다. (1에 가까울수록 온전히 기억한 것)
3. 셀 상태
- 삭제 게이트를 지난 값과 곱해져 일부 기억을 잃은 상태
- 입력 게이트에서 나온 두개의 값을 성분 곱한 결과값(=입력게이트에서 선택된 기억)과 전 시점에서 넘어온 일부 기억을 잃은 상태의 값과 더해진다.
- 즉, 삭제게이트는 이전 시점에서 넘어온 정보를 얼마나 반영할 지 결정하고, 입력게이트는 현재 시점의 정보를 얼마나 반영할지 결정한 후 더한다.
4. 출력 게이트
- 현재 시점 t의 x값과 이전 시점 t-1의 은닉 상태가 시그모이드를 지난 값
- 이 값은 현재 시점 t의 은닉상태를 결정한다.
- 셀 상태에 흐르는 값 (장기 상태)이 tanh 함수를 지나 -1~1의 값이 되고 위의 시그모이드를 지난 값과 곱해져 값이 걸러지는 효과가 발생하여 은닉 상태가 된다.
- 이 은닉 상태 (단기 상태)는 출력층과 다음 시점의 은닉상태로 보낸다.
3. GRU
- LSTM의 RNN 장기의존성 문제에 대한 해결책을 유지하면서, 연산량을 줄인 구조
- 즉, GRU는 성능은 LSTM과 유사하면서 연산량을 줄이고 복잡했던 LSTM구조를 간단화 시킴
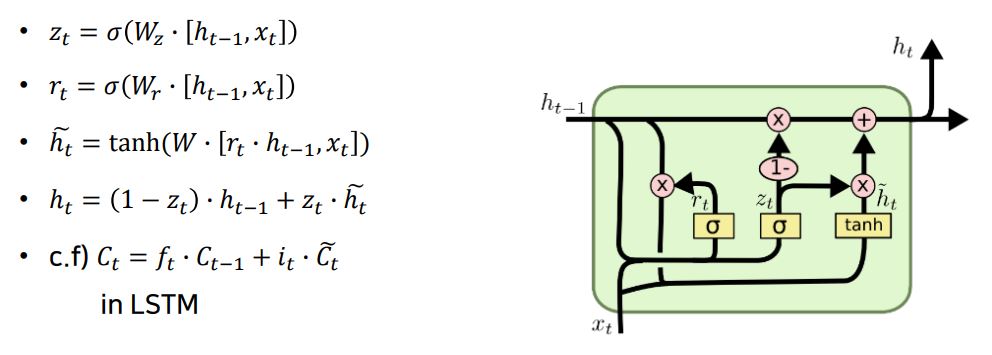
- LSTM에서는 입력, 삭제, 출력의 3개의 게이트가 존재했지만, GRU는 업데이트 게이트, 리셋 게이트 2개의 게이트가 존재한다.
참조 : https://wikidocs.net/22886
2. 피어 세션
1. 강의에 대한 토의
- RNN의 Gradient Vanishing, Exploding을 보완할 수 있는 방법?
- 초반 정보를 유지할 수 있는 방법 -> 양방향 RNN -> Concat or Sum
- Teacher Forcing
- RNN Language Model에서 시퀀스 순서대로 학습하면, 같은 단어의 입력은 무조건 같은 출력을 낼까?
2. 피어 미션
3. Conclusion
1. Embedding
2. 언어 데이터 전처리
3. PackedSquence
- 불필요한 pad 계산 줄이기
- pack_padded_sequence 입력 차원 -> 왜 transpose를 하는가?
'부스트캠프 AI Tech > 학습정리' 카테고리의 다른 글
| [Day 19] Transformer (0) | 2021.02.18 |
|---|---|
| [Day 18] NLP (자연어 처리) - 3 (0) | 2021.02.17 |
| [Day 16] NLP (자연어 처리) - 1 (0) | 2021.02.15 |
| [Day 15] Generative Models (0) | 2021.02.05 |
| [Day 14] RNN (0) | 2021.02.04 |
- Total
- Today
- Yesterday
- 공공데이터
- pandas
- P-Stage
- ResNet
- 네트워킹데이
- 부스트캠프 AI Tech
- 프로그래머스
- 백트래킹
- python
- dfs
- Unet
- 데이터연습
- 동적계획법
- 알고리즘
- 브루트포스
- Data Handling
- 이분탐색
- DeepLearning
- 코딩테스트
- DACON
- cnn
- NLP 구현
- 다이나믹프로그래밍
- C++
- 백준
- 데이터핸들링
- 그리디
- Vision AI 경진대회
- Unet 구현
- AI 프로젝트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |