
티스토리 뷰
[Day 19] Transformer
1. 강의 복습 내용
Transformer
1. Transformer
- 기존의 RNN 기반 seq2seq의 구조의 인코더-디코더를 따르면서도 RNN을 모두 제외하고 Attention만으로 구현한 모델
- 그럼에도 불구하고, 성능도 RNN보다 우수하다.
- 왜냐하면 기존의 RNN은 순차적인 처리를 해야만 했지만, Transformer는 Attention만을 사용하면서 Long-term dependency 를 해결하면서 동시에 병렬처리에 적합한 모델이기 때문이다.

2. Self Attention
- Query, Key, Value가 동일한 벡터의 출처에서의 연산이 이루어질 때
- 보통 인코더에서 이루어지고, 디코더에서는 Masked Decoder에서 이루어진다.
- 디코더의 인코더-디코더 연산에서는 Key와 Value는 인코더에서 온 벡터이고, Query가 디코더에서 온 벡터이다.
1) Encoder에서의 Self Attention

- 주어진 Query에 대해 모든 Key와 벡터의 유사도를 각각 구한다.
- 그리고 이 각각 구한 유사도를 가중치로 하여 (Softmax), Key와 맵핑되어 있는 Value에 반영한다.
- 즉, 어텐션 스코어(Q와 K의 유사도)를 통해 어텐션 분포를 얻고(Softmax(Q와K의 유사도)), 이를 사용하여 모든 V(Value)벡터를 가중합하여 구한 값이 어텐션 값(=Context Vector) 이다. -> 이를 각각의 쿼리마다 반복
2) Scaled dot-product Attention

- 트랜스포머에서는 두 벡터의 내적값을 스케일링 해준다.
- 임베딩 차원이 클수록 dot-product의 값이 커진다.
- 그렇게 되면 특정 노드의 Softmax 값이 1에 수렴하게 되어 gradient 값이 매우 작아진다.
- 학습 초기부터 small gradient 값이 발생하게 되면 학습이 정상적으로 이루어질 수 없다.
- 때문에 sqrt(d_{k})로 나눠 gentle softmax를 만드는 것이 목적이다.
3. Multi-head Attention
- 여러 Attention을 '병렬'로 수행하여 여러개의 feature를 담은 정보들을 수집하겠다는 아이디어
- 병렬로 모두 수행하면, 각 feature들을 담은 Attention head들을 concatenate 시켜준다.


3. Transformer 에서의 Encoder 구조

- Encoder의 구조는 크게 두개의 레이어로 나누어져있다.
- Multi-Head Attention과 Feed-Forward(NN)로 구분할 수 있다.
- 그리고 각각은 ResNet의 f(x)+x 의 구조인 Add(Residual connection)와 Norm(LayerNorm)이 포함되어 있다.
- CNN에서는 BatchNorm을 주로 사용하였지만, Transformer에서는 LayerNorm을 사용한다.
- 왜냐하면 Sequence 데이터이므로 BATCH별로 정규화하는 것보다, 각 Vector의 정규화가 필요하기 때문


4. Positional Encoding
- Encoder에서 Self-Attention 과정을 보면, 의문이 하나 들것이다.
- 각 Query마다 Key를 내적하고 Softmax를 지나 가중치화 시키고 이에 맵핑되는 Value를 연산하지만,
- Input 으로 들어온 Sequence를 단어들로 쪼개 각각 Query, Key, Value로 만들어주고 이것이 단어마다 순차적으로 입력이 들어가는 것이 아니므로 순차적으로 입력이 들어가는 RNN에 비하여 각 단어들의 '위치 정보'를 가질 수 없는 문제가 있다.
- 따라서, 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델에 입력할 필요가 있다.
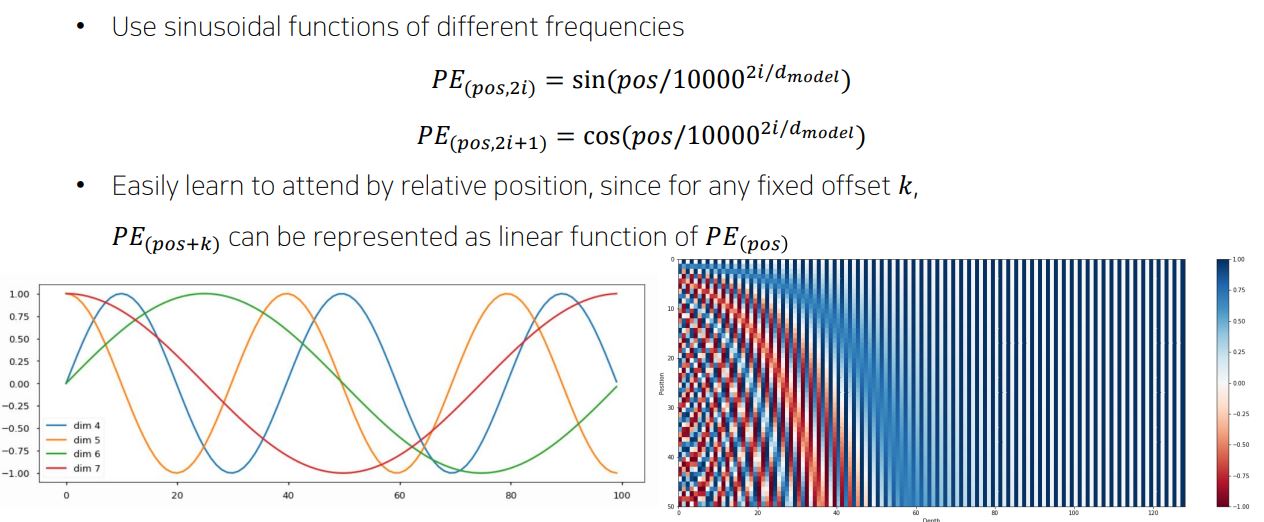
- 즉, 위치 정보들을 고유한 정보로써 표현하기 위해 Transformer 모델은 sin과 cos함수를 사용하였다.
5. Transformer 에서의 Decoder 구조
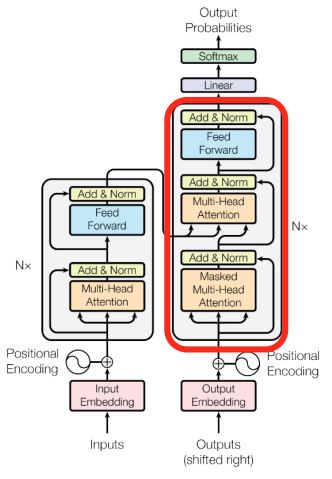
- Decoder는 3가지 구조로 이루어져있다.
- Masked Multi-Head Attention, Multi-Head Attention, Feed-Forward(NN)로 구성되어 있다.
1) Masked Multi-Head Attention
- 학습 중에, 디코더에서 입력을 <SOS>을 시작으로 단어들을 추론하기 시작하는데 이때 Attention이 생성되지 않은 단어들에 접근하여 유사도를 구하는 것을 방지하기 위해 Masking 해준다.
- 왜냐하면 RNN의 경우는 순차적으로 입력을 받기 때문에, 다음 시점을 예측할 때는 순차적으로 들어온 입력만을 가지고 추론하는데, 트랜스포머의 경우에는 입력을 모두 받기 때문에 다음 시점을 예측할 때, 미래 시점의 단어들까지 가지고 추론할 수 있기 때문이다. -> 미리보기에 대한 마스크
2) Multi-Head Attention
- 인코더의 Attention과 디코더의 Masked Attention은 Self-Attention이였던 반면, 여기서는 Key와 Value를 인코더의 마지막 층에서 온 행렬로 부터 얻는다. 반면 Query는 디코더의 첫번째 서브층의 결과 행렬로부터 얻는다.
- 그 외 수행과정은 모두 같다.
참조 : https://wikidocs.net/31379
2. 피어 세션
1. 강의에 대한 토의
1. scaled dot-product attention가 gradient에 미치는 영향 그리고 그 원리 -> Softmax
2. (Residual connection)을 ResNet의 f(x)+x 이 아닌 DenseNet의 cat(f(x),x)를 활용하지 않는 이유가 무엇일까?
3. LayerNorm을 사용하는 이유
3. Conclusion
처음에 Attention과 Transformer를 배울 때는 이해하기 힘들었었는데, 다시 깊게 들어가 재학습하니 드디어 이해가 좀 되는 것 같았다. 직접 구현을 해보면서 더 익혀볼 필요를 느꼈으며, f(x)+x가 아닌 cat(f(x),x)로 한번 바꿔서 돌려보고 싶다.
'부스트캠프 AI Tech > 학습정리' 카테고리의 다른 글
| [Day 21] 그래프 이론 기초 & 그래프 패턴 (0) | 2021.02.22 |
|---|---|
| [Day 20] Self-supervised Pre-training Models (0) | 2021.02.19 |
| [Day 18] NLP (자연어 처리) - 3 (0) | 2021.02.17 |
| [Day 17] NLP (자연어 처리) - 2 (0) | 2021.02.16 |
| [Day 16] NLP (자연어 처리) - 1 (0) | 2021.02.15 |
- Total
- Today
- Yesterday
- dfs
- DeepLearning
- Vision AI 경진대회
- Data Handling
- 백트래킹
- Unet
- 부스트캠프 AI Tech
- 프로그래머스
- 동적계획법
- Unet 구현
- 데이터연습
- NLP 구현
- ResNet
- DACON
- AI 프로젝트
- cnn
- 백준
- pandas
- 코딩테스트
- 브루트포스
- 알고리즘
- 이분탐색
- 공공데이터
- 그리디
- 데이터핸들링
- 다이나믹프로그래밍
- 네트워킹데이
- C++
- python
- P-Stage
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |