
 [Day 12] 최적화
[Day 12] 최적화
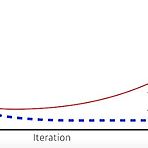
[Day 12] 최적화 1. 강의 복습 내용 1) Deep Learning - Optimization 더보기 Deep Learning - Optimization 1. Important Concepts in Optimization 1) Generalization - 일반화 성능을 높이는 것이 목적 - Training error 와 Test error의 차이 - Generalization Gap (즉, Generalization이 좋다 -> 모델의 성능(테스트결과)이 학습 데이터와 비슷하게 나온다) 2) Under-fitting vs Over-fitting Over-fitting - 학습 데이터에 대해서 잘 동작하지만, 테스트 데이터에 대해서 잘 동작하지 않는 현상 (과적합) Under-fitting - 네..
 [Day 11] 딥러닝 기초
[Day 11] 딥러닝 기초
[Day 11] 딥러닝 기초 1. 강의 복습 내용 1) 베이즈 통계학 더보기 베이즈 통계학 1. 조건부 확률 2. 베이즈 정리 - 조건부 확률을 이용하여 정보를 갱신하는 방법을 알려준다 - 새로운 데이터가 들어왔을 때 앞서 계산한 사후확률을 사전확률로 사용하여 갱신된 사후확률을 계산 할 수 있다. 3. 조건부 확률의 시각화 4. 조건부 확률과 인과관계 - 조건부 확률은 유용한 통계적 해석을 제공하지만, 인과관계를 추론할 때 함부로 사용해서는 안된다. (= 데이터가 많아져도 조건부 확률만 가지고 인과관계를 추론하는 것은 불가능) - 인과관계는 데이터 분포의 변화에 강건한 예측모형을 만들 때 필요 (단, 인과관계만으로는 높은 예측 정확도를 담보하기는 어렵다) *) 중첩요인 제거 - 인과관계를 알아내기 위해서..
 [Day 10] 시각화 / 통계학
[Day 10] 시각화 / 통계학
[Day 10] 데이터 시각화 / 통계학 1. 강의 복습 내용 1) 데이터 시각화 도구 더보기 시각화 도구 1. matplotlib - pyplot 객체를 사용하여 데이터를 표시 - pyplot 객체에 그래프들을 쌓은 다음 flush - Graph는 원래 figure 객체에 생성 - pyplot 객체 사용시, 기본 figure에 그래프가 그려짐 - Matplotlib는 Figure 안에 Axes로 구성 - Figure 위에 여러 개의 Axes를 생성 - 최대 단점 argument를 kwargs로 받음 - 고정된 argument가 없어서 확인 어려움 1) Figure & Axes - Subplot의 순서를 grid로 작성 2) Matplotlib Graph 1) Scatter - s: 데이터의 크기를 지정..
 [Day 09] Pandas / 통계학
[Day 09] Pandas / 통계학
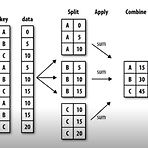
[Day 09] Pandas II / 통계학 1. 강의 복습 내용 1) Pandas II 더보기 Pandas II 1. GroupBy I - SQL Groupby 명령어와 같다 - Split -> apply -> combine - 과정을 거쳐 연산 1) Hierarchical index : GroupBy 명령의 결과물도 결국 dataframe : 두 개의 Column으로 groupby를 할 경우, index가 두개 생성 2) Unstack : Group으로 묶여진 데이터를 matrix 형태로 전환해줌 (유사 : Reset_index) 3) Swaplevel : index 레벨의 변경 -> 결과물만 바뀜 4) sort_index : index 레벨을 기준으로 정렬 5) sort_values : Value값..
 [Day 08] Pandas / 딥러닝 학습방법 이해하기
[Day 08] Pandas / 딥러닝 학습방법 이해하기
[Day 08] Pandas / 딥러닝 학습방법 이해하기 1. 강의 복습 내용 1) Pandas 더보기 Pandas - 구조화된 데이터의 처리를 지원하는 Python 라이브러리 - Panel data -> pandas - 고성능 array 계산 라이브러리인 numpy와 통합하여 강력한 '스프레드시트' 처리 기능을 제공 - 인덱싱, 연산용 함수, 전처리 함수등을 제공 - 데이터 처리 및 통계 분석을 위해 사용 1. 데이터 구조 정의 2. 데이터 로딩 data_url='URL' # Data URL df_datatable=pd.read_csv(data_url, sep='\s+', header=None) # csv 타입 데이터 로드, separate는 빈공간(space)으로 지정, Column은 없다(None)..
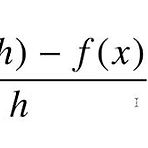 [Day 07] 경사하강법
[Day 07] 경사하강법
[Day 07] 경사하강법 1. 강의 복습 내용 더보기 경사하강법 1. 미분 - 변수의 움직임에 따른 함수값의 변화를 측정하기 위한 도구로 최적화에 제일 많이 사용하는 기법 import sympy as sym from sympy.abc import x sym.diff(sym.poly(x**2+2*x+3),x) #Poly(2*x+2,x,domain='ZZ') - 한 점에서 접선의 기울기를 알면 어느 방향으로 점을 움직여야 함수값이 증가/감소하는지 알 수 있다. - 미분값을 빼면 경사하강법(Gradient descent)이라 하며 함수의 극소값의 위치를 구할 때 사용한다. - 미분값을 더하면 경사상승법(Gradient ascent)이라 하며 함수의 극대값의 위치를 구할 때 사용한다. - 이렇듯, 경사하강/상..
 [Day 06] Numpy / 벡터 / 행렬
[Day 06] Numpy / 벡터 / 행렬
[Day 06] Numpy / 벡터 / 행렬 1. 강의 복습 내용 더보기 Numpy - Numpy는 파이썬으로 진행되는 모든 데이터 분석과 인공지능 학습에 있어 가장 필수적으로 이해해야 하는 도구 - Numpy는 Numerical Python의 약자로 일반적으로 과학계산에서 많이 사용하는 선형대수의 계산식을 파이썬으로 구현할 수 있도록 도와주는 라이브러리 1. Numpy 사용해보기 import numpy as np test_array=np.array([1,2,3,4],float) Numpy는 변수선언을 꼭 해줘야한다. C기반으로 작성되있기 때문에 동적타이핑 언어를 지원하지 않는다. a=[[1,2,3],[4,5,6],[4,5,6]] print(np.array(a).shape) # (3,3) a=[1,2,3..
 [Day 05] 파이썬으로 데이터 다루기
[Day 05] 파이썬으로 데이터 다루기
[Day 05] 파이썬으로 데이터 다루기 1. 강의 복습 내용 더보기 Exception - 프로그램을 사용할 때 일어나는 흔한 일들 - 프로그램 사용할 때 일어나는 오류들 1. 주소를 입력하지 않고 배송 요청 2. 저장도 안 했는데 컴퓨터 전원이 나감 3. 게임 아이템 샀는데 게임에서 튕김 -> 예상치 못한 많은 일(예외) 들이 생김 1. 예상 가능한 예외 - 발생 여부를 사전에 인지할 수 있는 예외 - 사용자의 잘못된 입력, 파일 호출 시 파일 없음 - 개발자가 반드시 명시적으로 정의 해야함 2. 예상 불가능한 예외 - 인터프리터 과정에서 발생하는 예외 - 리스트의 범위를 넘어가는 값 호출 혹은 정수 0으로 나눌 때 - 수행 불가시 인터프리터가 자동 호출 * 예외가 발생할 경우 후속 조치 등 대처가 필..
- Total
- Today
- Yesterday
- 부스트캠프 AI Tech
- 백준
- 다이나믹프로그래밍
- pandas
- Unet
- 알고리즘
- NLP 구현
- Vision AI 경진대회
- python
- 데이터핸들링
- DeepLearning
- DACON
- 이분탐색
- ResNet
- C++
- 데이터연습
- 그리디
- 브루트포스
- 코딩테스트
- 동적계획법
- AI 프로젝트
- Unet 구현
- Data Handling
- 공공데이터
- 네트워킹데이
- P-Stage
- dfs
- cnn
- 프로그래머스
- 백트래킹
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |